My Web Framework 3 (database1)

- My Web Framework 1부 - 라우팅
- My Web Framework 2부 - 템플릿 엔진
- My Web Framework 3부 - 데이터베이스 1
- My Web Framework 4부 - 데이터베이스 2
- My Web Framework 5부 - 세션과 쿠키
- My Web Framework 6부 - 보안
이번에는 데이터베이스 관련 기능을 추가해보자.
요구사항
데이터베이스와 관련하여 웹 프레임워크에 어떤 기능이 필요할까? 우선 데이터베이스 연결과 관련된 부분을 신경쓸 필요 없도록 웹 프레임워크가 알아서 관리해주면 좋을 것이다. 또, 데이터베이스에서 처리가 오래 걸릴 경우 이를 기다리지 않고 다른 웹 요청을 받아들일 수 있으면 좋을 것이다. 데이터 CRUD를 위한 가장 직관적인 사용법을 제공해주고, 쿼리 결과를 파이썬 객체로 매핑해주는 기능도 있으면 좋겠다. 정리하면 다음과 같다.
- 데이터베이스 연결 및 커넥션 풀링
- 동시성
- 직관적인 CRUD 인터페이스
- 객체-관계 매핑
우선 요구사항과 관련된 개념들을 하나씩 하나씩 살펴보고, 코딩도 해보자.
데이터베이스 연결
DB-API 2.0
데이터베이스와 상호작용하는 기능을 제공하려면, 데이터베이스에 연결하는 과정이 필요하다. 이를 살펴보기 전에 DB-API 2.0(Python Database API Specification v2.0)에 대해 알아보자.
DB-API 2.0는 파이썬 애플리케이션이 데이터베이스와 상호작용하기 위한 표준 인터페이스이다. 이러한 표준 인터페이스의 또다른 예로 ODBC가 있다.
DB-API 2.0은 connect(), 연결 객체(Connection Objects), 커서 객체(Cursor Objects) 등으로 구성된다.
DB-API 2.0을 준수하는 모듈은 연결 객체를 생성하기 위한 connect() 함수를 제공한다. 연결 객체는 close(), commit(), rollback(), cursor() 메소드를 통해 연결과 트랜잭션을 관리하고 커서 객체를 생성한다. 커서 객체는 description 등의 속성과 execute(), fetchall() 등의 메소드를 통해 데이터베이스와 상호작용한다.
sqlite3로 연결과 커서를 만들고 쿼리를 실행하는 다음 코드에서 이러한 구성 요소들을 확인할 수 있다.
import sqlite3 # DB-API 2.0을 준수하는 sqlite3 모듈(표준 라이브러리)
conn = sqlite3.connect('my.db') # connect(), 연결 객체
cursor = conn.cursor() # 연결 객체의 메소드, 커서 객체
cursor.execute('CREATE TABLE mytable (id INTEGER PRIMARY KEY)') # 커서 객체의 메소드
conn.commit() # 연결 객체의 메소드
cursor.close() # 커서 객체의 메소드
conn.close() # 연결 객체의 메소드
하는 김에 mysqlclient 패키지 예제 코드도 확인해보자. 똑같은 DB-API 2.0 인터페이스를 사용하기 때문에 패턴이 완전히 같은 것을 볼 수 있다.
import MySQLdb # DB-API 2.0을 준수하는 mysqlclient 패키지의 MySQLdb 모듈
conn = MySQLdb.connect( ... )
cursor = conn.cursor()
cursor.execute( ... )
conn.commit()
cursor.close()
conn.close()
이제 DB-API 2.0이 무엇인지는 대강 알 것 같다. 그러면, 웹 프레임워크는 DB-API 2.0을 직접 구현해야 할까? 만약 그렇다면 소켓 통신(서버-클라이언트 기반 데이터베이스)이나 파일 읽기(파일 기반 데이터베이스)를 사용해서 연결을 만들고, 커서를 만들고, SQL 실행을 요청하고, 트랜잭션을 관리하는 등의 c 코드를 직접 작성해야 할 것이다.
다행히 많은 파이썬 웹 프레임워크들이 DB-API 2.0을 직접 구현하지는 않는 것 같다. django의 경우 connect(), close(), commit(), rollback(), cursor() 메소드 등을 가진 BaseDatabaseWrapper의 인스턴스로 데이터베이스 연결을 나타내고 있다(Represent a database connection). 하지만 이는 Wrapper의 성격을 띄고 있으며, 실제 데이터베이스 연결은 DatabaseWrapper 객체에서 임포트한 MySQLdb나 sqlite3 등 외부 모듈이 담당한다.
커넥션 풀링
한번 만든 연결을 메모리에 계속 유지하다가 필요할 때 재사용하는 기술을 커넥션 풀링이라고 한다. 기업이 지원자의 정보를 인재풀에 보관하는 모습과 유사하다. DB-API 2.0의 경우 연결 객체를 재사용하는 것이라고 보면 되겠다.
커넥션 풀링은 매번 연결을 만들 때 발생하는 오버헤드(TCP 핸드쉐이크 등)를 줄이는 역할과, 연결 객체의 수를 제한하는 역할을 한다.
실제로 커넥션 풀링이 도움이 되는지 다음 코드로 확인해보자. 함수를 10000번씩 실행하면서 소요 시간을 측정한다. sqlite3 모듈 혹은 sqlalchemy의 NullPool을 사용해 연결 객체를 매번 새로 생성한 경우 1초 이상이 소요된 반면, QueuePool을 사용해 1개의 연결 객체를 재사용할 경우 0.1초만 소요되었다. 함수들의 실행 순서를 바꿔봐도 동일한 결과가 나온다. 확실히 연결 객체 생성에 오버헤드가 있음을 알 수 있다.
또, 파일 기반 데이터베이스에서도 커넥션 풀링이 가능하다는 것을 확인할 수 있다. sqlalchemy의 경우 파일 기반 sqlite3에 QueuePool을 기본값으로 커넥션 풀링을 적용한다는 내용이 여기에 나와 있다.
import sqlite3
from sqlalchemy import create_engine, text
from sqlalchemy.pool import QueuePool, NullPool
import timeit
DATABASE_URL = 'sqlite:///test.db'
nopool = create_engine(DATABASE_URL, poolclass=NullPool) # 연결을 풀링하지 않음
pool = create_engine(DATABASE_URL, poolclass=QueuePool, pool_size=1, max_overflow=0)
def using_sqla(engine):
with engine.connect() as connection: # with 문에서 빠져나오면 close()
pass
def using_sqlite():
conn = sqlite3.connect('test.db')
conn.close()
elapsed1 = timeit.timeit("using_sqlite()", number=10000, globals=globals()) # 1.122
elapsed2 = timeit.timeit("using_sqla(nopool)", number=10000, globals=globals()) # 1.401
elapsed3 = timeit.timeit("using_sqla(pool)", number=10000, globals=globals()) # 0.103
DB-API 2.0는 데이터베이스 연결에 대한 기본적인 인터페이스만 제공할 뿐, 커넥션 풀링에 대한 부분은 제공하지 않는다. django처럼 직접 구현하거나, sqlalchemy, psycopg2(postgresql) 등을 이용해야 한다. 커넥션 풀링은 큐를 사용하여 구현할 수 있겠다.
커넥션 풀링을 사용할 때 연결 객체의 수명에 주의해야 한다. 데이터베이스는 일정 시간(MySQL의 경우 wait_timeout)이 경과한 비활성 연결을 종료할 수 있는데, 이를 인지하지 못한 웹 프레임워크가 유효하지 않은 연결 객체를 재사용하려고 할 수 있다. 연결 객체의 수명은 wait_timeout 시간보다 짧아야 한다.
동시성
다수의 웹 요청과 데이터베이스 작업을 동시에 처리하면 응답 시간을 줄일 수도 있을 것이다. 대형 프로젝트라면 웹 애플리케이션 서버를 여러 대로 확장하는 경우 등 여러 시나리오를 고려해야하므로 개발 방향이 달라지겠지만, 여기서는 단순하게 단일 서버에서 단일 웹 애플리케이션 프로세스만 실행한다고 가정한다.
동시성은 여러 작업이 동시에 실행되는 것처럼 보이는 상태를 말한다. 병렬성은 동시성에 포함되는 개념으로, 여러 프로세서나 코어에서 여러 작업이 실제로 동시에 실행되는 것을 말한다.
동시성을 얻기 위해서는 멀티 스레딩, 멀티 프로세싱, 코루틴, 경량 스레드 등을 활용할 수 있다. 파이썬 공식문서 1, 2에서는 동시성을 달성하기 위한 도구들로 threading, multiprocessing, concurrent.futures, queue, asyncio 등을 소개하고 있다. 이들에 대해 살펴보기 전에 일단 동기와 비동기가 무엇인지 알아보자.
동기, 비동기
작업이 처리되는 순서가 차례대로인 방식을 동기 방식이라고 하며, 차례대로가 아닌 방식을 비동기 방식이라고 한다.
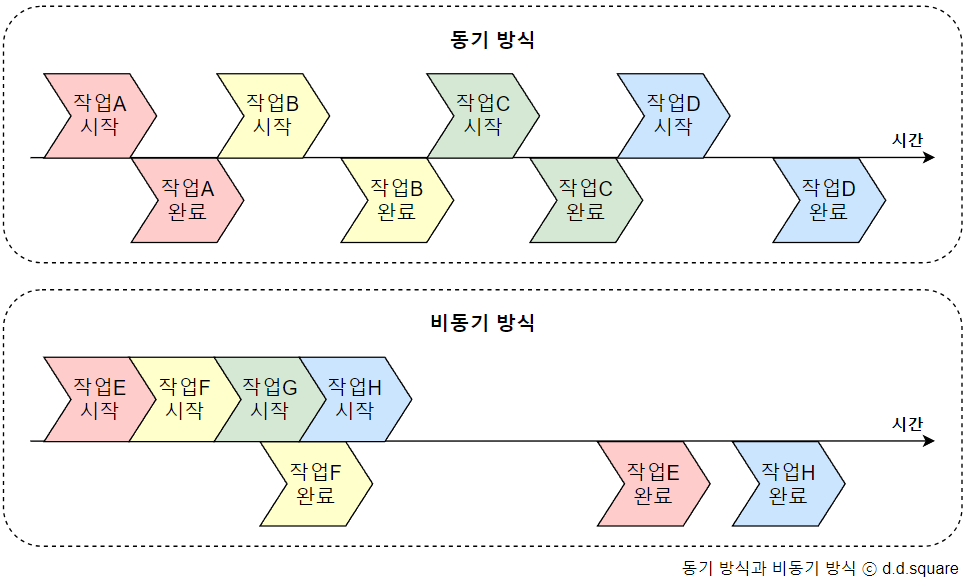
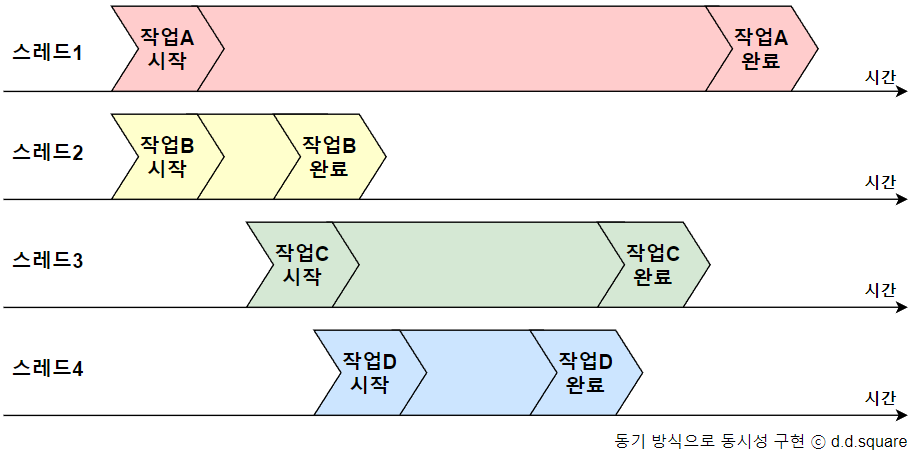
동기 방식으로도 동시성을 얻을 수 있다. 아래는 동기 방식으로 단일 작업을 수행하는 여러 스레드들이 작업 시작 순서에 상관없이 비동기적으로 작업을 완료하는 모습이다. 이러한 방식보다는 아래에서 다룰 코루틴이 권장된다.
멀티 스레딩
하나의 프로세스에서 여러 스레드를 생성하여 각각의 작업을 수행하도록 할 수 있다. 스레드는 프로세스의 메모리 공간을 공유하므로 여러 스레드가 공유 자원에 접근할 때 문제가 일어날 수 있다. 또한, 파이썬 멀티 스레딩에는 GIL이라는 장치가 관여한다.
뮤텍스(Mutex, Mutual Exclusion)와 세마포어는 공유 자원 문제를 해결하기 위한 대표적인 기법이다. threading.Lock은 파이썬에서 뮤텍스를 구현한 것이다. acquire()와 release()를 사용해 잠금을 얻거나 해제함으로써 한 번에 하나의 스레드만 공유 자원에 접근하도록 허용한다. 멀티 스레드 환경에서 파일 기반 sqlite3에 접근할 때 이를 활용할 수 있을 것이다. 더 복잡한 상황에서는 threading.Semaphore, threading.Condition 등을 고려할 수 있겠다.
GIL(Global Interperter Lock)은 파이썬 스레드가 한번에 하나씩 실행되도록 하는 장치로, 파이썬 멀티 스레딩을 안전하게 만들어주지만 성능을 떨어트리기도 하는 양날의 검이다(파이썬에서 제거될 예정).
이 글에 따르면, 파이썬은 한 시점에 GIL을 획득하고 있는 하나의 스레드만 실행하도록 구현되어 있다고 한다. 기본 시간이 경과되거나 명시적으로 해제를 명령할 경우 스레드의 GIL이 해제되고, 해제된 GIL을 획득한 다른 스레드가 실행된다.
파이썬 코드를 실행 중인 스레드(GIL을 획득한 스레드)는 기본 시간(5ms, sys.getswitchinterval())이 경과하면 GIL을 해제한다. 이 경우 5ms 간격으로 두 스레드가 번갈아 실행되어 마치 동시에 실행되는 것처럼 보인다.
단, 무조건 5ms인 것은 아니고, 실행 중인 작업(operation)이 완료되지 않았다면 GIL을 해제하지 않는다고 한다. 해당 글의 예시에서는 c_sleep(2) 함수가 내부적으로 파이썬 확장 코드를 실행하여 2초 동안 GIL을 묶어두고 있는 모습을 보여준다.
c 등의 저수준 언어로 작성된 파이썬 확장은 GIL을 명시적으로 해제할 수 있다고 한다. 이 경우 GIL을 명시적으로 해제한 파이썬 확장과, GIL을 획득한 다른 스레드는 실제로 동시에 실행할 수 있다. time.sleep()의 내부 구현은 Py_BEGIN_ALLOW_THREADS와 Py_END_ALLOW_THREADS로 GIL을 명시적으로 해제하고 있다.
정리하면, 멀티 스레딩에서 파이썬 코드(리스트를 사용하거나 변수에 값을 대입하는 등)와 파이썬 코드는 동시 실행 효율이 낮고, 파이썬 코드와 저수준 언어로 작성된 코드는 동시 실행 효율이 높다. DB-API 2.0 저수준 구현 라이브러리를 사용하는 코드는 멀티 스레딩을 활용해 어느 정도 성능을 높일 수 있다고 생각된다. 다만, 가능하다면 코루틴을 사용하는 것이 좋겠다.
멀티 프로세싱
1개의 프로세스에서 이루어지는 멀티 스레딩과 달리, 여러 개의 프로세스를 생성하여 각각의 작업을 수행하도록 할 수 있다. 각각의 프로세스는 별도의 메모리 공간을 가지고 독립적으로 실행되므로 공유 자원과 관련된 문제가 없다. 또한, GIL의 영향을 받지 않는다. 데이터베이스 같은 I/O 작업보다는 CPU 위주의 작업에 효율적이라고 한다.
concurrent.futures
ThreadPoolExecutor, ProcessPoolExecutor, Future를 제공하여 보다 간편하게 멀티 스레딩과 멀티 프로세싱을 사용할 수 있도록 한다.
코루틴(asyncio)
코루틴은 하나의 스레드 내에서 여러 개의 루틴과 일시 중지 메커니즘(yield)을 사용하여 실행 흐름을 제어하는 기법이다. 일반적인 함수(서브루틴)는 코드를 모두 실행한 후 제어를 반환하는 블로킹 방식이지만, 코루틴은 실행과 일시 중지를 번갈아가며 다른 작업의 실행을 허용하는 논블로킹 방식이다. 스레드에 비해 메모리와 CPU 연산 등의 소모가 적어 동시성을 구현하는 데 더 효율적이라고 한다. 멀티 스레딩과 마찬가지로 공유 자원 문제가 발생할 수 있으므로 필요한 경우 Lock 등을 사용해야 할 것이다.
asyncio는 파이썬 비동기 입출력 라이브러리로, 비동기 함수(코루틴)들을 동시에 실행할 수 있게 해준다. 스레드가 아닌 코루틴을 사용하기 때문에 GIL로부터 자유롭다. 문서에 따르면 asyncio의 용도 중 하나로 데이터베이스 연결 라이브러리가 있다.
시뮬레이션 코드를 통해 코루틴의 성능을 느껴보자.
먼저 다음과 같이 비동기 IO 함수, 동기 IO 함수, WSGI 서버, ASGI 서버(uvicorn)를 준비한다.
import asyncio
from wsgiref.simple_server import make_server
import uvicorn
async def async_io_bound():
await asyncio.sleep(2)
def sync_io_bound():
time.sleep(2)
def wsgi_app(environment, start_response):
if environment['PATH_INFO'] == '/io':
sync_io_bound()
status = '200 OK'
headers = [('Content-type', 'text/plain; charset=utf-8')]
body = [b'Hello World']
start_response(status, headers)
return body
async def asgi_app(scope, receive, send):
if scope["path"] == "/io":
await async_io_bound()
assert scope['type'] == 'http'
await send({
'type': 'http.response.start',
'status': 200,
'headers': [[b'content-type', b'text/plain']],
})
await send({
'type': 'http.response.body',
'body': b'Hello, world!',
})
threading.Thread(target=make_server('', 3000, app=wsgi_app).serve_forever).start()
threading.Thread(target=lambda: uvicorn.run(asgi_app, port=5000)).start()
20번의 IO 요청과 1000번의 non-IO 요청에 대한 처리 시간을 측정한다. 총 1020개의 fetch 코루틴이 생성된다. asyncio.Semaphore는 동시에 실행되는 코루틴의 수를 제한하여 WSGI fetch에서 발생하는 retry를 줄여주는 역할을 한다.
semaphore = asyncio.Semaphore(50) # 동시에 실행할 코루틴의 최대 개수를 제한
fetch_log = {'wsgi_ok':0, 'wsgi_retry':0, 'asgi_ok':0, 'asgi_retry':0}
async def fetch(mode, url, retry_max=5, retry_delay=1):
global fetch_log
async with semaphore:
async with aiohttp.ClientSession() as session:
for retry in range(retry_max):
try:
async with session.get(url) as response:
fetch_log[mode+"_ok"] += 1
if mode == 'wsgi' and '/io' in url:
print("------------- BLOCKING -------------")
return await response.text()
except Exception as e:
fetch_log[mode+"_retry"] += 1
await asyncio.sleep(retry_delay)
# 20번의 IO, 1000번의 non-IO
async def test(mode, port):
start = time.time()
tasks = []
for i in range(20):
tasks.append(fetch(mode, f'http://localhost:{port}/io'))
for i in range(50):
tasks.append(fetch(mode, f'http://localhost:{port}/'))
await asyncio.gather(*tasks)
return time.time() - start
async def main():
wsgi_time = await test('wsgi', 3000)
asgi_time = await test('asgi', 5000)
print(f"[WSGI] : {wsgi_time}s")
print(f"[ASGI] : {asgi_time}s")
print(fetch_log)
if __name__ == '__main__':
asyncio.run(main())
WSGI는 동기 방식 IO 작업에서 40초 동안 블로킹(2초 * 20회)이 발생하였으며, 해당 시간 동안 non-IO 요청이 처리되지 않고 대기하는 현상이 있었다(BLOCKING 문구). ASGI는 비동기 IO 작업에서 블로킹이 발생하지 않았으며, 처리 순서 역시 비동기적인 형태를 보였다. 만약 IO 작업에서 블로킹되는 시간이 더 늘어난다면 격차는 더 커질 것이다.
또한, WSGI 서버는 여러 요청을 동기 방식으로 처리하기 때문에 요청이 한꺼번에 몰릴 경우 이를 제대로 소화하지 못했다. 이로 인해 많은 요청들이 실패하고 재시도가 이루어졌다. ASGI 서버는 요청을 비동기 방식으로 처리하여 이러한 현상이 발생하지 않았다.
일부 WSGI 요청들은 재시도로 인한 딜레이가 발생했으나, 재시도 전까지 공백 기간 동안 다른 요청이 처리되는 것을 감안하면 실질적인 딜레이 총합은 크지 않을 것으로 판단된다(1초 정도로 추정).
...
INFO: 127.0.0.1:5639 - "GET / HTTP/1.1" 200 OK
INFO: 127.0.0.1:5640 - "GET / HTTP/1.1" 200 OK
INFO: 127.0.0.1:5641 - "GET / HTTP/1.1" 200 OK
INFO: 127.0.0.1:5642 - "GET / HTTP/1.1" 200 OK
INFO: 127.0.0.1:5049 - "GET /io HTTP/1.1" 200 OK
INFO: 127.0.0.1:5138 - "GET /io HTTP/1.1" 200 OK
INFO: 127.0.0.1:5280 - "GET /io HTTP/1.1" 200 OK
INFO: 127.0.0.1:5363 - "GET /io HTTP/1.1" 200 OK
INFO: 127.0.0.1:5474 - "GET /io HTTP/1.1" 200 OK
INFO: 127.0.0.1:5577 - "GET /io HTTP/1.1" 200 OK
[WSGI] : 49.28419756889343s
[ASGI] : 8.261517763137817s
{'wsgi_ok': 1020, 'wsgi_retry': 247, 'asgi_ok': 1020, 'asgi_retry': 0}
내용 중에 혹시 틀린 부분이 있다면 메일(rebolation@naver.com)을 보내주세요!
참고
 My Web Framework 4 (database2)
나만의 파이썬 마이크로 웹 프레임워크
My Web Framework 2 (template)
나만의 파이썬 마이크로 웹 프레임워크
My Web Framework 4 (database2)
나만의 파이썬 마이크로 웹 프레임워크
My Web Framework 2 (template)
나만의 파이썬 마이크로 웹 프레임워크